Introduction
There are two sides to a coin and AI is no exception. AI’s versatility is what makes it useful across a vast array of use cases. And yet, it carries several risks when left unchecked. Recognizing the urgency of addressing these twin forces of promise and peril, the Reserve Bank of India (RBI) constituted the FREE-AI Committee and, in August 2025, released the Framework for Responsible, Ethical, and Effective AI Regulation (FREE-AI).
The Free-AI framework is a much needed respite for the Indian financial sector. This framework could possibly steer the Indian financial sector towards large-scale AI adoption, whilst balancing innovation with systemic stability and ethical governance.
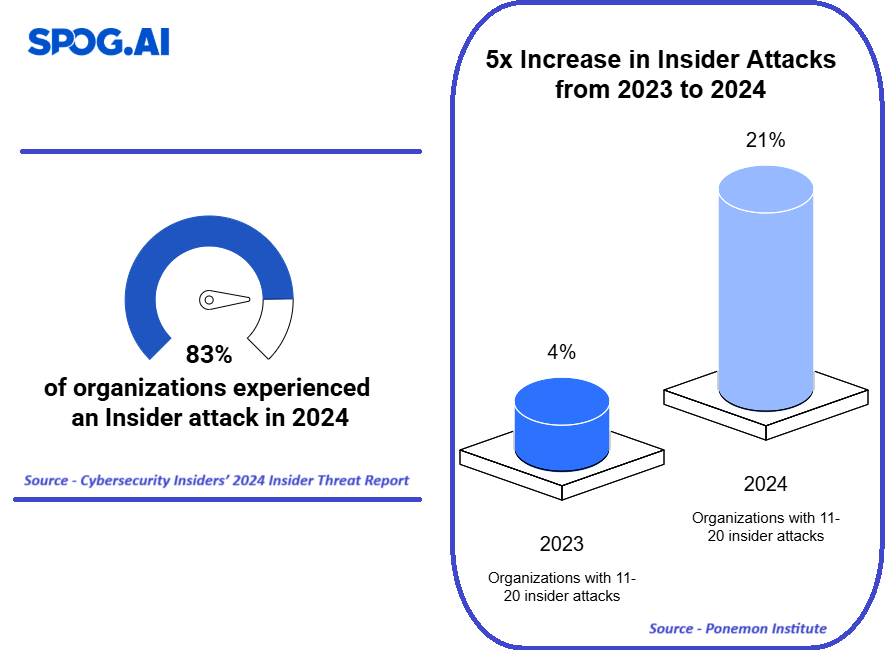
According to the survey conducted by RBI, AI adoption among supervised financial entities remains limited, primarily due to low uptake by smaller institutions such as Urban Co-operative Banks (UCBs) and Non-Banking Financial Companies (NBFCs).
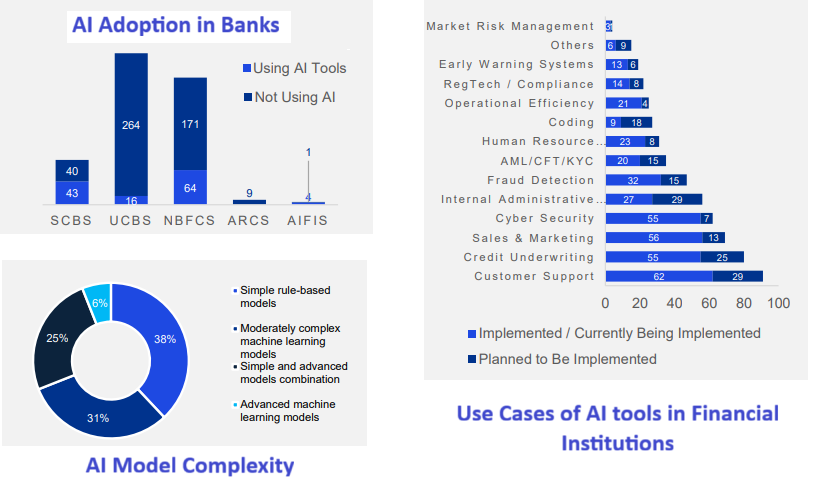
Where AI is being used , the most common use cases are in low-risk, high-volume applications such as customer support, sales and marketing, credit underwriting, and cybersecurity. The survey also indicated that the majority of institutions relied on simple rule based non learning AI models and moderately complex ML models, with limited adoption of advanced AI models.
Financial institutions expressed significant concerns about adopting advanced AI due to risks such as data privacy breaches, cybersecurity vulnerabilities, governance gaps, and reputational damage. Many lacked formal governance structures, with only about one-third having board-level oversight and even fewer maintaining incident response mechanisms. Data management practices were fragmented, with no dedicated policies for AI training datasets and limited use of tools for bias detection or model monitoring.
Despite these challenges, the demand for regulation was overwhelming: 85% of respondents voiced a strong need for a clear regulatory framework to guide responsible AI deployment.
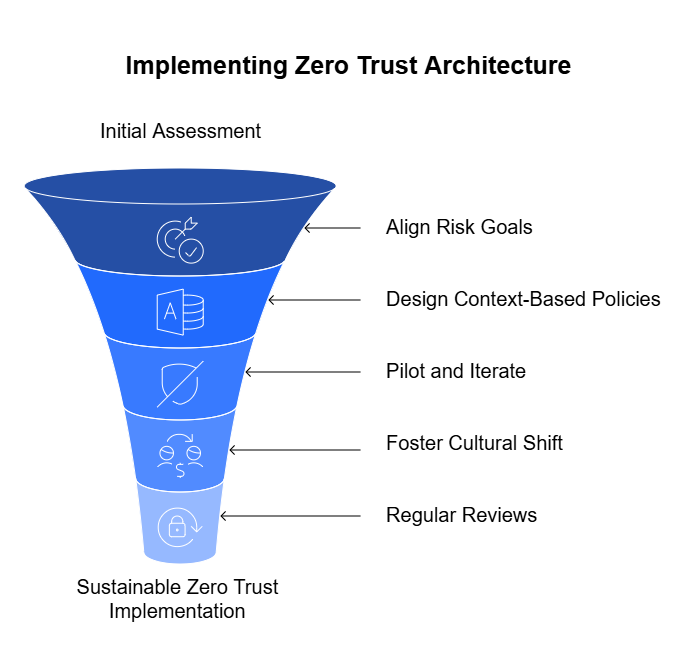
It is this reality that shaped the RBI’s FREE-AI framework—a unifying vision anchored in seven ethical Sutras and a six-pillar architecture that integrates innovation enablement (Infrastructure, Policy, Capacity) with risk mitigation (Governance, Protection, Assurance). Together, they provide the scaffolding for a financial ecosystem where AI augments human intelligence, deepens inclusion, and strengthens institutional integrity.
Why This Framework, Why Now?
India stands at the heart of AI transformation. With its vast, multilingual, and digitally connected population, the country presents a unique opportunity to use AI as a lever for financial inclusion. Advances in multilingual and multimodal AI, capable of understanding regional languages and low-literacy inputs, can bridge long-standing gaps in access to banking, credit, and insurance.
The FREE-AI Framework is designed to ensure that India’s financial AI revolution is guided by responsibility, explainability, and resilience. As cited in the report some of the AI Adoption barriers that the framework aims to address include:
- Bias and Fairness Concerns
When AI models are trained on incomplete or skewed datasets, they can reinforce existing social or financial biases—affecting credit approvals, pricing, or inclusion. FREE-AI promotes fairness-by-design through better data governance, bias detection tools, and regular model audits to ensure outcomes remain equitable and inclusive.
- Lack of Explainability
Opaque “black-box” models undermine both regulatory scrutiny and customer trust. The framework embeds Explainable AI (XAI) as a design principle, requiring documentation, transparency tools, and interpretability standards so that every automated decision can be understood and justified.
- Operational and Systemic Risks
Errors in AI systems can scale rapidly across high-volume transactions, leading to financial or reputational loss. FREE-AI addresses this through continuous model validation, red-teaming, and human-in-the-loop oversight to prevent unchecked automation and systemic contagion.
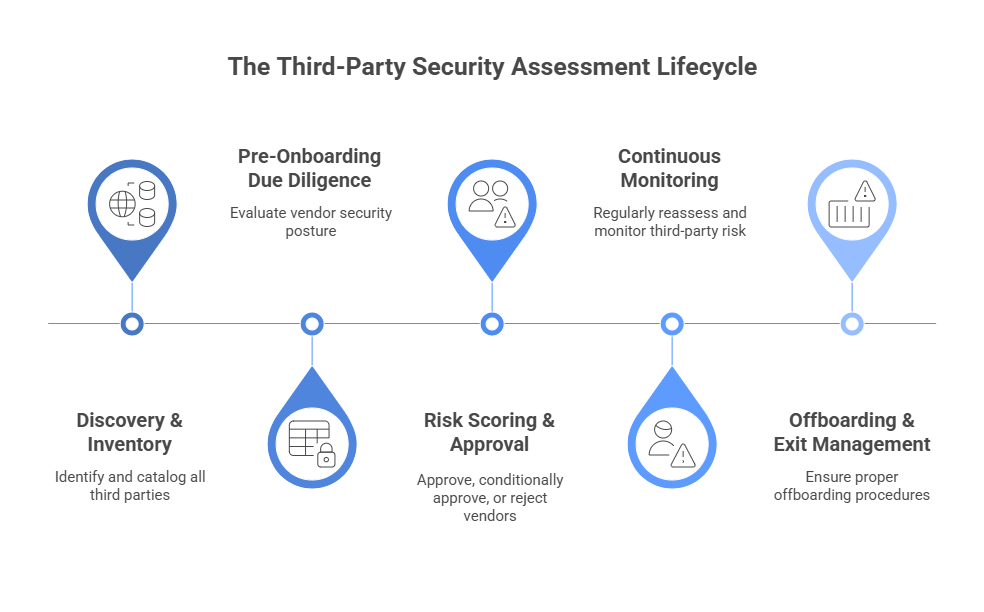
- Third-Party Dependencies
Many smaller institutions depend on external vendors or cloud-based AI systems, often without visibility into how these models are trained or governed. The framework strengthens vendor accountability by requiring contractual compliance with ethical and data protection standards, and promotes the creation of a repository of audited AI models.
- Cybersecurity Threats
AI can be both a defensive asset and a vulnerability. FREE-AI calls for AI-specific cybersecurity measures, such as adversarial testing, Business Continuity Plans (BCPs), and privacy-preserving techniques like federated learning to guard against model manipulation and data breaches.
- Consumer Protection and Ethical Concerns
AI-driven financial decisions can directly impact customers’ rights and trust. The framework embeds consumer protection and ethics into its core—mandating transparency in AI usage, clear grievance redressal mechanisms, and the principle of “People First”, ensuring human welfare remains central to all AI applications.
Who Does FREE-AI Apply To?
The FREE-AI Framework applies to all entities operating within India’s regulated financial ecosystem that develop, deploy, or depend on Artificial Intelligence systems in the course of their business.
Its scope is intentionally broad—recognizing that AI use in finance extends far beyond core banking—to ensure uniform ethical and governance standards across the entire sector.
1. Regulated Entities (REs) under RBI Supervision
FREE-AI directly applies to all RBI-regulated entities, including:
- Scheduled Commercial Banks (SCBs)
- Small Finance Banks (SFBs) and Payments Banks
- Non-Banking Financial Companies (NBFCs)
- All-India Financial Institutions (AIFIs) such as NABARD, SIDBI, EXIM Bank, and NHB
- Urban Co-operative Banks (UCBs) and State/District Co-operative Banks
These institutions are expected to implement the framework’s governance, protection, and assurance mechanisms, including AI policies, model inventories, disclosure standards, and internal audit processes.
2. Fintechs, Technology Service Providers (TSPs), and Third-Party Vendors
Given the extensive outsourcing of AI tools and analytics in the sector, FREE-AI also extends to fintech partners, data analytics firms, RegTech providers, cloud platforms, and AI vendors that design or manage models used by regulated entities.
- Such partners are required to meet the same standards of data privacy, fairness, explainability, and accountability that apply to their financial-institution clients.
- Regulated entities remain ultimately accountable for the actions and outcomes of third-party AI systems they employ—a principle central to FREE-AI’s “Accountability Sutra.”
3. Supervisory and Regulatory Bodies
The framework also envisions coordination among India’s financial-sector regulators and supervisory agencies—including RBI, SEBI, IRDAI, and PFRDA—to harmonize AI oversight, share risk intelligence, and establish a National Repository of Audited AI Models.
This multi-agency approach prevents regulatory fragmentation and supports consistent risk management across markets and products.
4. Applicability Across the AI Lifecycle
FREE-AI’s provisions span the entire AI lifecycle, covering:
- Design and development of models
- Training and testing using financial or consumer data
- Deployment and monitoring in production environments
- Post-implementation audits and incident reporting
In other words, it applies not only to the use of AI, but also to how it is built, maintained, and governed—ensuring continuous accountability from conception to retirement.
5. Proportionate Application Based on Risk
Recognizing the diversity of entities and use cases, FREE-AI adopts a risk-based, proportionate approach:
- High-risk systems (e.g., credit scoring, AML, fraud detection) face enhanced governance and audit requirements.
- Medium-risk systems (e.g., marketing, customer analytics) require periodic reviews.
- Low-risk automation tools (e.g., back-office process bots) are subject to lighter oversight.
This graduated framework ensures that compliance expectations remain practical and scalable, particularly for smaller institutions and early-stage fintechs.
The Seven Sutras — Guiding Principles
At the heart of the FREE-AI Framework lies a set of seven ethical anchors—known as the Seven Sutras of Responsible AI. These Sutras serve as the moral and operational compass for all stakeholders in India’s financial ecosystem. Inspired by India’s philosophical tradition of balance between progress and prudence, they translate abstract ideals of ethics and fairness into actionable design and governance principles.
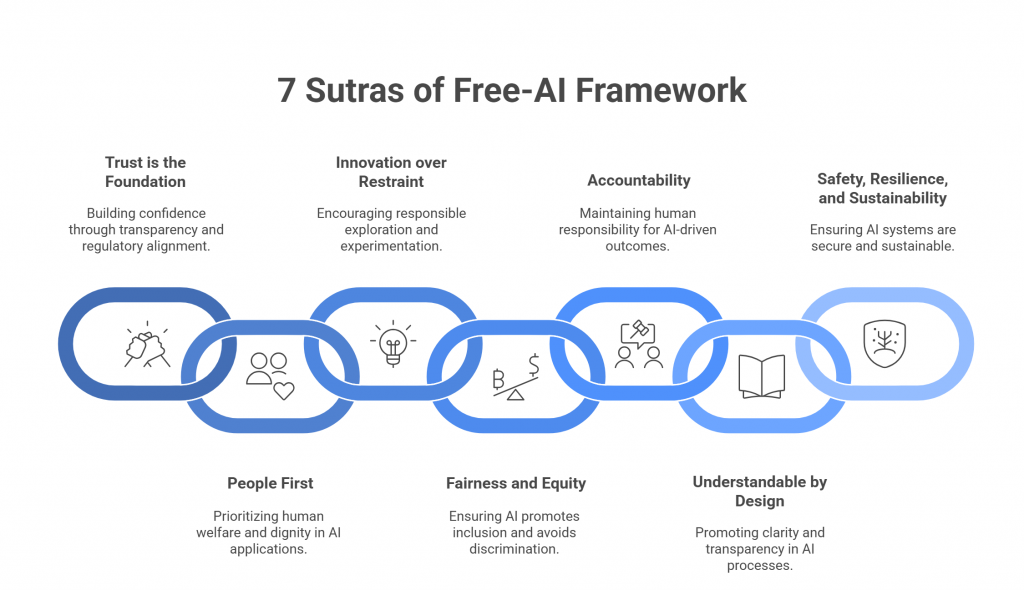
Each Sutra encapsulates a core value that the RBI believes must underpin every AI system used in finance—ensuring that technology serves people, institutions remain accountable, and innovation advances in harmony with public trust.
1. Trust is the Foundation
Trust forms the bedrock of financial systems—and by extension, of AI in finance. Without trust, even the most sophisticated algorithms lose legitimacy. This Sutra calls for AI systems that are transparent, auditable, and aligned with regulatory expectations. Institutions must ensure that every AI model deployed strengthens, not erodes, consumer confidence in the financial system.
In practice: Building trust means clear communication with customers when AI is used in decision-making, providing avenues for explanation and redress, and maintaining transparency in model outcomes and data handling.
2. People First
AI should always augment human judgment, not replace it. This principle asserts that humans remain accountable for decisions, even when aided by automation. The goal is to design systems that empower employees and protect consumers—keeping human welfare, dignity, and fairness at the center.
In practice: Implement “human-in-the-loop” controls for critical decisions like loan approvals, fraud detection, or risk scoring, ensuring final authority rests with qualified personnel.
3. Innovation over Restraint
This Sutra reflects the RBI’s belief that regulation should enable innovation responsibly, not stifle it. Financial institutions are encouraged to explore AI’s potential in safe, supervised environments such as AI sandboxes—spaces that promote experimentation while embedding ethical oversight and risk controls.
In practice: Use the AI Innovation Sandbox and shared data infrastructure to prototype, validate, and deploy AI solutions safely, ensuring they meet fairness and explainability standards before full rollout.
4. Fairness and Equity
AI should be a tool for inclusion, not exclusion. Models trained on biased or incomplete data risk perpetuating discrimination. This Sutra mandates fairness-by-design—embedding bias detection, data validation, and equitable access mechanisms throughout the AI lifecycle.
In practice: Conduct fairness testing, document datasets and model logic, and use diverse training data to minimize bias. Prioritize inclusive design that reflects India’s multilingual, socio-economic diversity.
5. Accountability
Responsibility for AI decisions cannot be outsourced to algorithms or third-party vendors. This Sutra ensures that humans—and institutions—remain answerable for every AI-driven outcome. Every regulated entity must establish clear governance structures, assign ownership of AI risks, and maintain auditable trails for decisions.
In practice: Appoint a Chief AI Ethics Officer (CAIEO) or equivalent role, and ensure that all AI models undergo internal and third-party reviews for compliance and ethical alignment.
6. Understandable by Design
AI must be explainable, interpretable, and transparent. This Sutra mandates that model logic, data sources, and decision outcomes be clearly understood by developers, regulators, and customers alike. The goal is to replace black-box opacity with clarity and confidence.
In practice: Maintain Model Cards, Data Sheets, and explainability dashboards that document model purpose, data lineage, and decision pathways. Use explainable ML techniques where possible.
7. Safety, Resilience, and Sustainability
AI systems should be secure, robust, and designed for long-term sustainability. As models become more autonomous, they must withstand adversarial attacks, data drift, and operational shocks without compromising integrity or consumer protection.
In practice: Incorporate cybersecurity testing, business continuity plans (BCPs), and energy-efficient AI practices. Regularly validate and retrain models to adapt to evolving data and regulatory conditions.
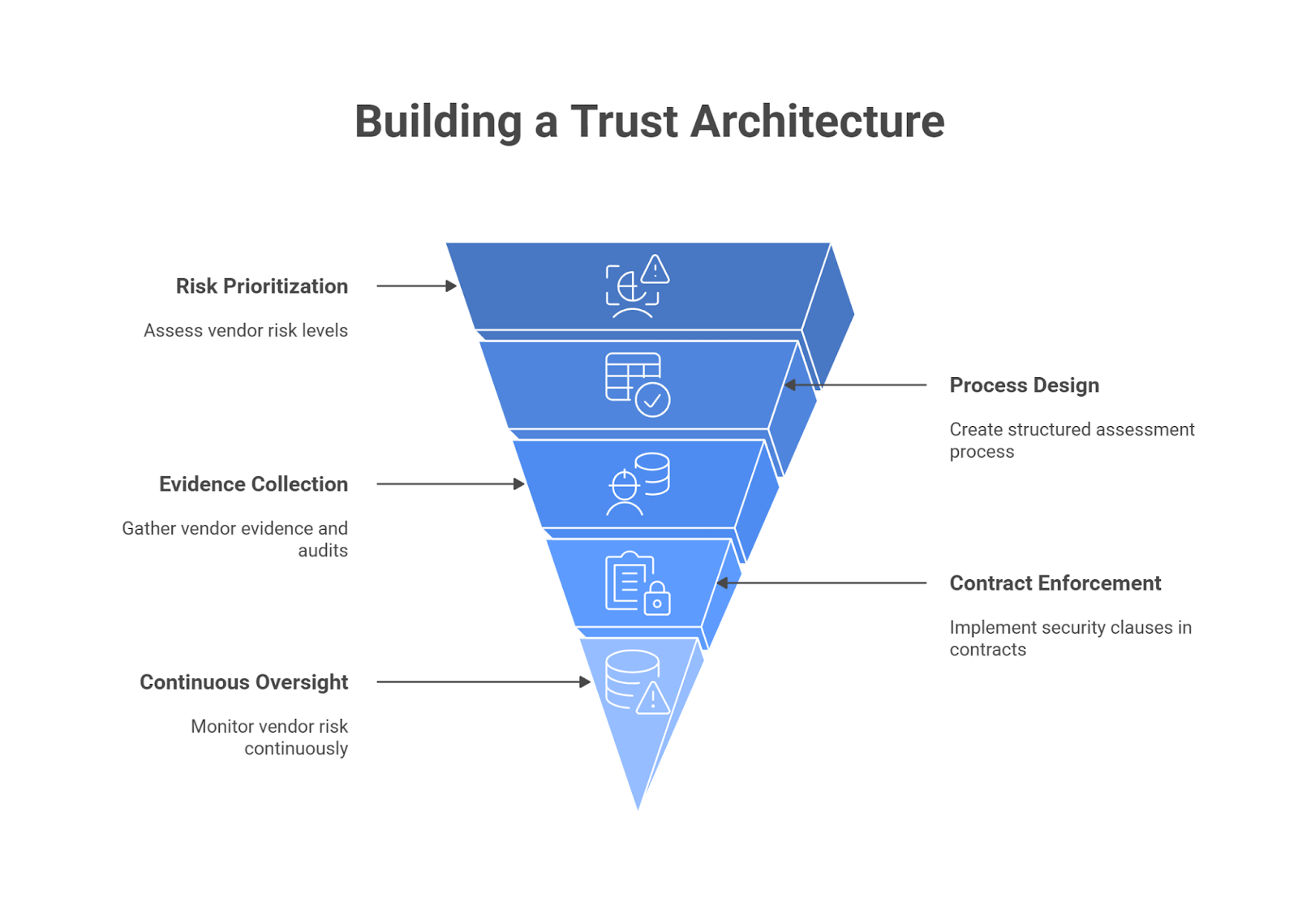
From Principles to Practice — Two Sub-Frameworks and Pillar-wise Recommendations
The FREE-AI Framework transforms the RBI’s ethical vision into a practical governance blueprint, bridging the gap between principle and implementation.
While the Seven Sutras define how AI should behave, the framework’s two sub-structures—Innovation Enablement and Risk Mitigation—outline how institutions should act to achieve that ideal.
Together, they form a six-pillar architecture supported by 26 specific recommendations that guide financial entities, regulators, and technology partners in deploying AI safely, responsibly, and effectively.
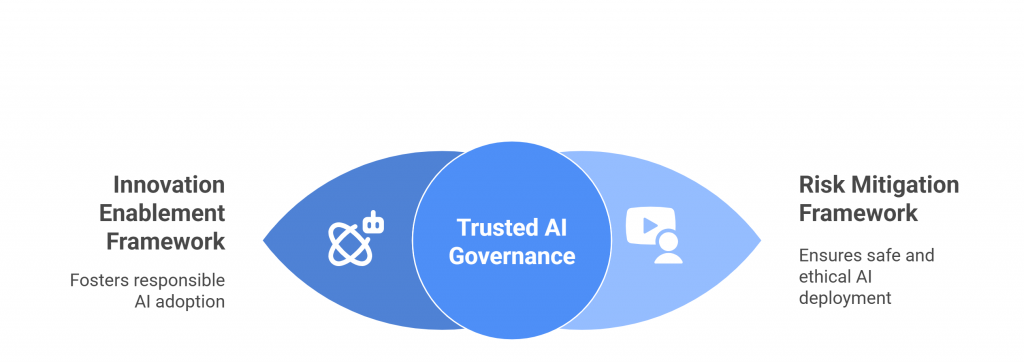
The Two Sub-Frameworks: Balancing Innovation and Oversight
1. Innovation Enablement Framework
Designed to promote responsible experimentation and adoption, this sub-framework provides the structural foundation for safe AI innovation.
It rests on three pillars:
- Infrastructure — Building the digital and data backbone for responsible AI.
- Policy — Creating adaptive, enabling regulations that evolve with technology.
- Capacity — Strengthening institutional and human capabilities for AI readiness.
2. Risk Mitigation Framework
Focused on governance and safety, this framework ensures that every AI system deployed in finance is auditable, resilient, and ethically aligned.
It too rests on three pillars:
- Governance — Defining accountability, oversight, and ethical responsibility.
- Protection — Safeguarding data, consumers, and financial stability from AI-related risks.
- Assurance — Establishing continuous evaluation, audit, and transparency mechanisms.
The two frameworks are interdependent—Innovation Enablement provides the tools and confidence to innovate, while Risk Mitigation provides the guardrails to innovate safely.
Pillar-wise Recommendations
The FREE-AI Committee outlined 26 recommendations, grouped across these six pillars.
Below is a summary of the key priorities under each.
A. Innovation Enablement Framework
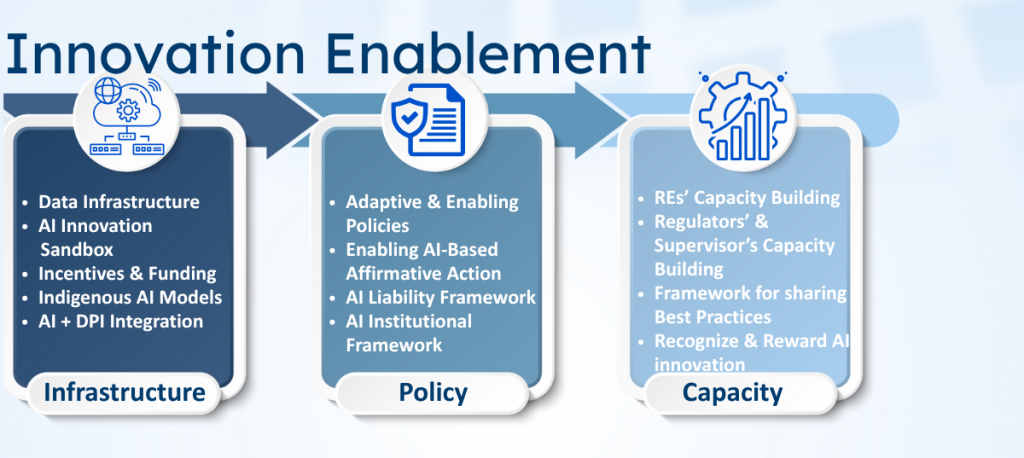
Pillar 1: Infrastructure
- Financial Sector Data Infrastructure —
Establish a shared, high-quality data ecosystem integrated with IndiaAI’s AI Kosh, featuring standardized formats, metadata, and privacy-preserving technologies to support model training and validation. - AI Innovation Sandbox —
Create a secure experimentation environment where banks, fintechs, and technology providers can test AI models using anonymized or synthetic data before full deployment. - Incentives and Funding Support —
Launch targeted financial support and shared computing resources for smaller institutions (UCBs, NBFCs) to democratize AI access and reduce cost barriers. - Indigenous Financial Sector AI Models —
Develop domain-specific Indian AI models (LLMs, SLMs) for finance as public goods, minimizing reliance on foreign systems. - Integration with Digital Public Infrastructure (DPI) —
Enable responsible use of AI within India’s digital stack (UPI, Aadhaar, Account Aggregator) to enhance inclusion, personalization, and fraud prevention.
Pillar 2: Policy
- Adaptive and Enabling Policies —
Create flexible, technology-neutral regulatory guidelines that evolve with AI advancements and emerging risks. - AI-based Affirmative Action —
Encourage AI applications that promote inclusion and equitable access, particularly for underserved populations and MSMEs. - AI Liability Framework —
Define clear accountability for AI-driven decisions, clarifying liability between institutions, developers, and vendors. - AI Institutional Framework —
Establish a standing multi-stakeholder body comprising regulators, academia, and industry to continuously review AI risks, standards, and compliance best practices.
Pillar 3: Capacity
- Capacity Building within Regulated Entities (REs) —
Train leadership and staff on AI governance, risk management, and ethical design through RBI-endorsed programs. - Capacity Building for Regulators and Supervisors —
Develop specialized training modules and an AI Centre of Excellence to enhance supervisory expertise. - Framework for Sharing Best Practices —
Create a collaborative platform for knowledge exchange among banks, fintechs, and technology partners. - Recognize and Reward Responsible AI Innovation —
Institute awards or incentive programs for ethical AI practices, encouraging innovation with integrity.
B. Risk Mitigation Framework
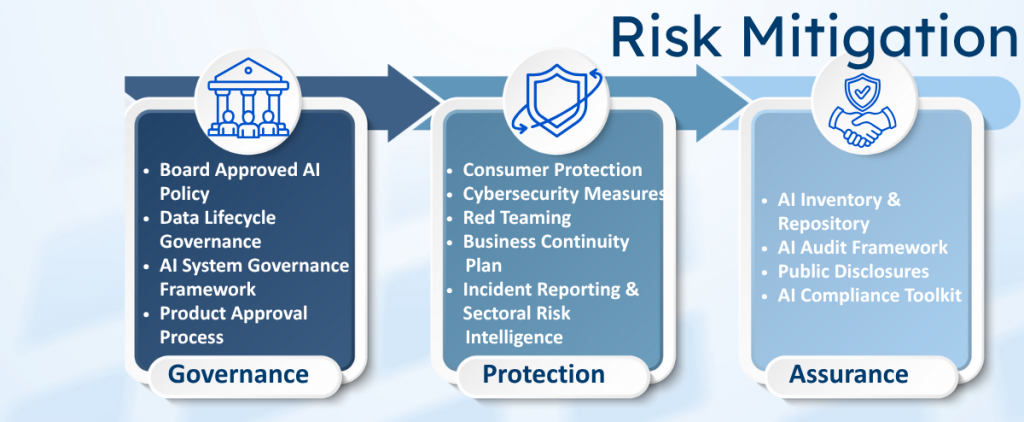
Pillar 4: Governance
- Board-Approved AI Policy —
Require each regulated entity to adopt a Board-approved AI policy defining governance, oversight, and model risk management protocols. - Data Lifecycle Governance —
Implement strong internal controls covering data collection, storage, quality assurance, and retention for AI training and deployment. - AI System Governance Framework —
Establish robust lifecycle management for all AI systems, including approval processes, performance monitoring, and accountability mapping. - Product Approval Process —
Integrate AI-specific risk evaluation into the product approval process, ensuring ethical and regulatory compliance before launch.
Pillar 5: Protection
- Consumer Protection Measures —
Safeguard customers through transparent disclosures, grievance mechanisms, and human oversight in AI-led interactions. - Cybersecurity Controls —
Strengthen defences against AI-specific threats such as model manipulation, adversarial attacks, and data breaches. - Red-Teaming and Adversarial Testing —
Mandate regular stress-testing of AI systems to identify vulnerabilities and strengthen resilience. - Business Continuity for AI Systems —
Integrate AI contingencies into Business Continuity Plans (BCPs) to ensure service stability during model failures or cyber incidents. - AI Incident Reporting and Sectoral Risk Intelligence —
Introduce a sector-wide reporting mechanism for AI-related incidents, enabling collective learning and non-punitive risk sharing.
Pillar 6: Assurance
- AI Inventory and Repository —
Maintain an internal registry of all AI systems in use, and contribute anonymized summaries to a sector-wide repository maintained by RBI. - AI Audit Framework —
Implement periodic, independent audits of AI models based on risk tier and use-case sensitivity. - Public Disclosures by Regulated Entities —
Mandate annual reporting on AI governance practices, including model usage, bias mitigation, and accountability measures. - AI Compliance Toolkit —
Provide a standardized toolkit for self-assessment and benchmarking against RBI’s ethical and operational expectations.
Implementation Roadmap — Timelines and Milestones (2025–2028)
The FREE-AI Framework envisions a phased, proportionate rollout that allows financial institutions to progressively strengthen their AI governance maturity while preserving operational continuity.
Rather than imposing immediate compliance mandates, the RBI adopts a “learn–adapt–implement” approach—building institutional capacity and regulatory clarity in parallel.
The roadmap is divided into three implementation phases, followed by an ongoing improvement cycle.
Implementation Timeline Overview
| Year | Phase | Focus Area | Key Deliverables |
| 2025–26 | Phase 1 | Awareness & Capacity | AI policies, committees, inventory, training, sandbox setup |
| 2026–27 | Phase 2 | Governance & Integration | Data lifecycle management, audits, fairness testing, coordination body |
| 2027–28 | Phase 3 | Full Implementation | AI audits, repository, reporting, sectoral harmonization |
| Post-2028 | Phase 4 | Continuous Evolution | Certification, periodic reviews, research partnerships, cross-sector sandboxing |
Phase 1: Awareness and Capacity Building (FY 2025–26)
Objective: Build understanding, capacity, and foundational governance structures across the financial ecosystem.
Key Milestones:
- Publication and Dissemination of FREE-AI Guidelines (Aug 2025): RBI circulates the finalized framework and supporting documentation to all regulated entities (REs).
- Establishment of Responsible AI Committees: Banks, NBFCs, and other REs form internal governance bodies to oversee AI risk management and ethics.
- Baseline Assessments: Entities conduct gap analyses using the AI Compliance Toolkit, mapping current practices against FREE-AI expectations.
- Regulator and Industry Training: Launch of RBI-led workshops and AI capacity-building programs for supervisors, compliance officers, and developers.
- Creation of an AI Innovation Sandbox: Pilot environment set up for safe testing of new AI models and Generative AI use cases under controlled conditions.
Deliverables by end of FY 2026:
- Board-approved AI policy frameworks.
- Institutional AI inventories and baseline risk classification.
- Initiation of data governance and model documentation processes.
Phase 2: Institutionalization and Governance (FY 2026–27)
Objective: Move from policy formulation to structured governance, testing, and assurance.
Key Milestones:
- Operationalization of AI Policies: Entities begin implementing governance mechanisms for AI oversight, including model approval processes and lifecycle management.
- Launch of AI Audit and Monitoring Frameworks: RBI issues detailed guidance on audit standards and reporting templates for AI risk assessment.
- Integration with Digital Public Infrastructure (DPI): Responsible AI applications begin leveraging Aadhaar, UPI, and Account Aggregator ecosystems for inclusive finance.
- Introduction of Fairness and Explainability Testing: Mandatory bias and explainability checks implemented for all high-risk AI use cases.
- Sector-wide Coordination: Establishment of a Standing Committee on Responsible AI to harmonize standards across regulators (RBI, SEBI, IRDAI, PFRDA).
Deliverables by end of FY 2027:
- Fully functional AI governance committees and data governance frameworks.
- Implementation of model risk controls, bias audits, and vendor accountability provisions.
- Public disclosures on AI use and ethical safeguards in annual reports.
Phase 3: Full Implementation and Supervisory Integration (FY 2027–28)
Objective: Achieve full operational readiness, continuous assurance, and regulatory integration.
Key Milestones:
- Mandatory AI Audits for High-Risk Systems: Independent audit regimes established for credit scoring, AML, fraud detection, and other critical models.
- Sectoral AI Repository Operationalized: Entities begin submitting metadata and audit summaries to the National Repository of Audited AI Models, improving transparency and risk monitoring.
- AI Incident Reporting Framework Activated: Standardized templates introduced for reporting model failures, bias incidents, or cyber vulnerabilities.
- Cross-Regulatory Data Sharing: Supervisory coordination across financial regulators enables unified oversight of AI risks.
- Publication of RBI’s Annual AI Governance Review: Sector-wide progress, best practices, and challenges published for public accountability.
Deliverables by end of FY 2028:
- AI governance and audit practices integrated into routine regulatory compliance.
- Continuous monitoring of AI risks and performance metrics.
- Enhanced consumer protection mechanisms and grievance redress systems.
Phase 4: Continuous Improvement and Evolution (Post-2028)
Objective: Institutionalize responsible AI as an enduring cultural and operational norm.
Key Milestones:
- Periodic Framework Review: RBI conducts a triennial review of FREE-AI to update ethical, technical, and regulatory standards in line with global best practices.
- AI Ethics Certification Program: Launch of certification tracks for AI auditors, ethics officers, and compliance professionals.
- Collaborative Research and Innovation: Partnerships between academia, industry, and regulators to advance explainability, fairness metrics, and sustainability.
- Expansion of the AI Innovation Sandbox: Inclusion of cross-border and multi-sectoral pilots to test emerging technologies (e.g., quantum AI, GenAI-driven risk modeling).
Long-term Outcomes:
- A financial ecosystem that is AI-ready, risk-aware, and ethically governed.
- Institutional alignment between innovation and integrity.
- Global recognition of India as a leader in responsible AI regulation.
Conclusion: A Phased Path to Responsible AI Leadership
The RBI’s FREE-AI roadmap reflects a measured, capacity-first approach—prioritizing education and infrastructure before enforcement.
By 2028, all regulated entities are expected to have mature AI governance systems, institutionalized ethics frameworks, and transparent assurance mechanisms in place.
In the longer term, FREE-AI aims not merely to regulate technology but to cultivate a culture of responsible intelligence—where every AI decision in finance upholds the values of trust, fairness, and human accountability that define India’s financial system.